
集合进阶
ArrayList
- 创建对象
1 | ArrayList< String > list = new ArrayList<>(); |
- 添加
1 | list.add(" "); |
- 删除
1 | list.remove(" "); |
- 修改
1 | list.set( 索引, 要修改的值) |
- 查询
1 | list.get(索引) |
其中,如果想让另一个ArrayList复制一份,可以用ArrayList
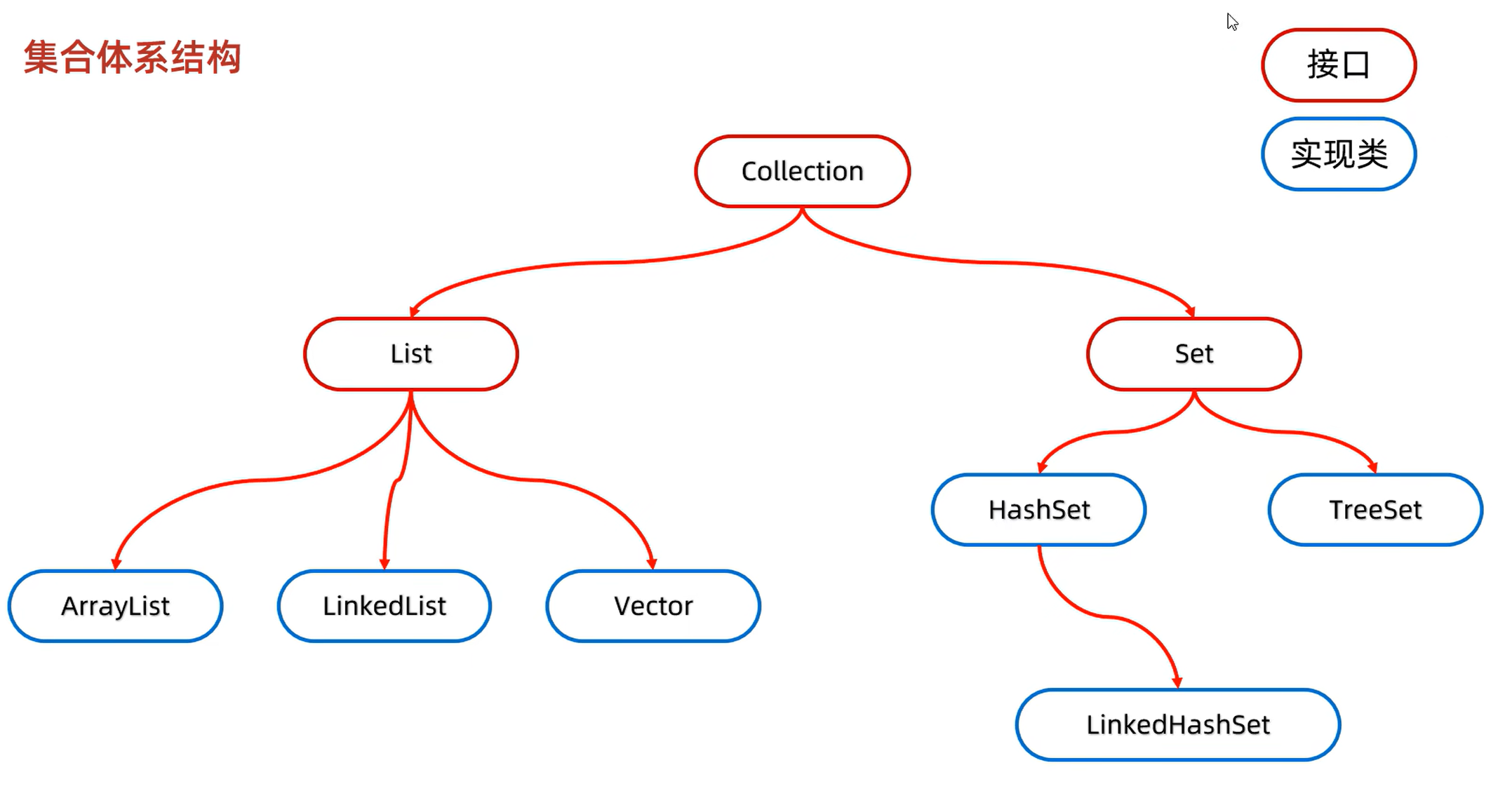
List系列集合:添加的元素是有序,可重复,有索引
有序:输入的和输出的是一样(即输入1,2,3,就输出1,2,3)
可重复:元素可重复
有索引:可以通过索引获取每个元素
Set系列集合:无序,不重复,没索引
无序:存和取的顺序有可能不同
Collection
因为Collection是一个接口,所以不能直接创建它的对象,因此只能创建实现类的对象ArrayList
Collection< String > coll = new ArrayList<>();
1.添加元素
coll.add(“aaa”);
2.清空元素
coll.clear();
3.删除元素
coll.remove(“aaa”);
4.判断元素是否包含
boolean result = coll.contains(“bbb”);
5.判断是否为空
boolean result2 = coll.isEmpty();
6.获取集合长度
int s = coll.size();
通用遍历方式
迭代器遍历
Iterator< String > it = list.iterator();//获取集合的零索引
boolean flag = it.hasNext();//判断当前位置是否有元素
String str = it.next();//获取当前元素,并把指针移到下一个位置
可以做出一个循环
Iterator< String > it = list.iterator();
while(it.hasNext()){
String str = it.next();
System.out.println(str);
}
List特有的列表迭代器
就是在原有的基础上可以添加和删除元素
ListIterator< String > it = list.ListIterator<>();
while(it.hasNext()){
String str = it.next();
if(“bbb”.equals(str)){
it.add(“qqq”);
}
System.out.println(str);
}
增强for
只有单列集合和数组才能用
格式:
for(元素的数据类型 变量名 :数组或集合){
}
例如
for(String s : list){
System.out.println(s);
}
快捷键:coll.for
lambda表达式遍历
格式(采用匿名内部类的方法):
coll.forEach(new Consumer< String >() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
其中源码为: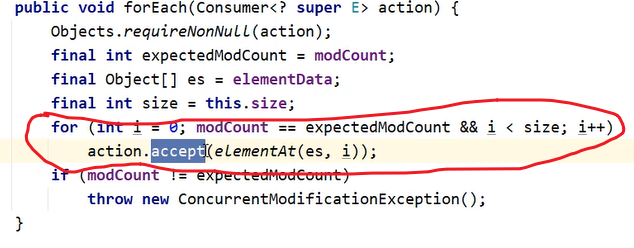
也就是说foreach就是普通的for循环,而通过重写accept来规定循环的内容
而lambda表达式遍历为:
coll.foreach(s -> System.out.println(s));
lambda表达式
格式:
() -> {
}
例如:
Integer[] a = {2,1,4,6,7,8,56,4,3};
Arrays.sort(a, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
其中的匿名内部类可以简化成
Arrays.sort(a, (Integer o1, Integer o2) -> {
return o1 - o2;
}
);
注意:
lambda表达式只能用于匿名内部类和函数式接口(有且仅有一个抽象方法的接口)
List特有的方法
1.创建集合
List< String > list = new ArrayList<>();
2.添加元素
list.add(“aaa”);
list.add(“bbb”);
list.add(“ccc”);
3.在指定索引处添加元素
void add(int index, E element)
list.add( 1, “qqq”);
会输出 aaa , qqq , bbb , ccc
也就是说在指定位置添加元素不会覆盖掉原来的元素,而是会往后挪
4.删除指定索引处的元素,返回被删除的元素
E remove(int index)
String s = ist.remove(0);
如果是Integer类型的,如
List< Integer > list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
此时想把’1’去掉,我们可以想到用 list.remove(1);
但这个’1’在此代码的作用是去掉索引为1的元素,也就是2
原因:
当方法发生重载时,会优先调用实参和形参类型相同的那个
1是int类型,而index也是int类型,所以此处的1是索引
所以应该:
Integer i = Integer.valueOf(1);
list.remove(i);
也就是把’1’转化为Integer类型
5.修改索引处的元素,返回被修改的元素
E set(int index, E element)
6.返回索引处的元素
E get(int index)
ArrayList底层逻辑

泛型深入
泛型类
修饰符 class 类名 <类型>{
}
如:
public class ArrayList
}
其中“E”为任意字母,但通常是E
泛型方法
修饰符 <类型> 返回值类型 方法名 (类型 变量名){
}
如
public < T > void move(T t){
}
泛型接口
修饰符 interfere 接口名 < E >{
}
泛型通配符
就是?
其中包含:
?extends E 表示传递E或E所有的子类型
?super E 表示传递E或E所有的父类型
数据结构
Set系列
特点
Set系列集合:无序,不重复,无索引
无序:存和取的顺序有可能不同
不重复:元素不可重复
无索引:不可以通过索引获取每个元素
- 创建一个Set集合的对象
Set< String > s = new HashSet<>();
- 添加元素
s.add(“sss”); //第一次添加的时候成功,返回true
s.add(“sss”); //第二次添加的时候失败(因为元素不可重复),返回false
- 打印元素(同List)
- 迭代器遍历
- 增强for
- lambda
HashSet
特点
无序,不重复,无索引

- 创建对象
1 | Student s1 = new Student("1",1); |
- 如果没有重写hashCode方法的话,不同对象计算出的哈希值就不一样
1 | System.out.println(s1.hashCode()); |
重写的话就在Student类中按alt+ins,选择图上所示,之后next即可

哈希碰撞的话abc和acD会出现
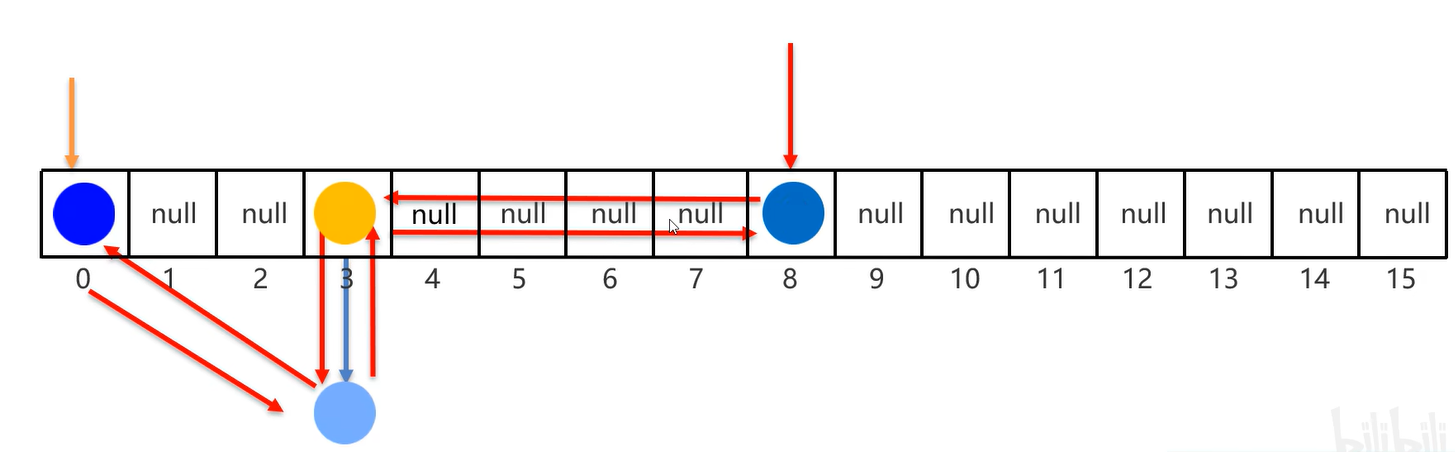
- HashSet底层逻辑

- 第一点中的
0.75意思是:当数组中有16X0.75=12个元素时,数组将扩容为原来的两倍,即变为24 - 第二点中数据的位置的计算公式为
int index = (数组长度 - 1) & 哈希值;
LinkedHashSet
- LinkedHashSet底层逻辑
特点
有序,不重复,无索引
(有序是因为有双链表)

红黑树
规则

默认节点是红色的(效率高,因为调整的地方要少)
具体讲解跳转黑马
TreeSet
特点

- 创建TreeSet对象
TreeSet< Integer > st = new TreeSet<>();
- 添加元素
ts.add(3);
ts.add(1);
ts.add(2);
最后还是会按大小排序输出
规则

比较方法
自然排序
在类(比如Student)实现Comparable接口,重写里面的抽象方法,在指定比较规则
1 | @Override |
比较器排序
创建TreeSet对象时,传递Comparator制定规则
1 | TreeSet<String> ts = new TreeSet<>(new Comparator<String>() { |
其中o1表示当前要添加的元素,o2表示红黑树中已经存在都在的元素
单列集合总结
( )
)
双列集合
- 特点


Map的常见API
Map是双列集合的顶层接口,他的功能是双列集合都可以继承使用的

- 创建Map集合对象Map<String,String> m = new HashMap<>();
其中添加元素时
- 如果键不存在,会直接把键值对对象添加到Map集合当中
- 如果键存在,会把原有的键值对对象覆盖,把被覆盖的键值对对象返回
Map的遍历方法
键找值
- 获取所有的键,把这些键放到一个单列集合当中
Set
- 遍历单列集合,获取每一个键
for (String key : keys) {
System.out.println(key);
//利用Map集合的键获取对应的值
String value = m.get(key);
System.out.println(key+”=”+value);
}
键值对对象遍历
- 通过一个方法获取所有的键值对对象,返回一个Set集合
Set<Map.Entry<String, String>> e = m.entrySet();
- 遍历e这个集合,获取每一个键值对对象
Lambda表达式
- 匿名内部类为
m.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String s, String s2) {
System.out.println(s+s2);
}
});
- Lambda表达式为
m.forEach((s,s2) -> System.out.println(s+s2));
foreach底层
其实就是调用第二种方法,获取每一个key和value,在调用accept方法
HashMap
特点

LinkedHashMap
- 由键决定:有序,不重复,无索引
原理:底层数据结构依然是哈希表,只是多了个双链表
TreeMap
- 与TreeSet一样,都是红黑树结构
- 对键进行排序,默认从小到大,也可以自己修改排序规则
1 | TreeMap<Character,Integer> tm = new TreeMap<>(new Comparator<Character>() { |
或者
在类中传入接口Comparable

再alt+enter修改

可变参数
当执行某个函数的时候,因为不清楚所需参数的多少,所以可以用可变参数
格式:
public static 类型 函数名(E…参数名(一般为args)){
}
1 | package Test2; |
细节:
- 方法中的形参中可变参数只能有一个
- 如果有其他的参数,可变参数要写在最后
Collections
Collections不是集合,而是集合的工具类
工具类的特点:直接名称.即可调用方法
